Our data are from the 2007 Text Retrieval Conference (TREC) corpus. Before feeding the emails to our classifiers, we need to pre-process the emails. The goal is to create a feature matrix with rows being the email and columns being the features.
Pre-processing: Creating the Feature Matrix
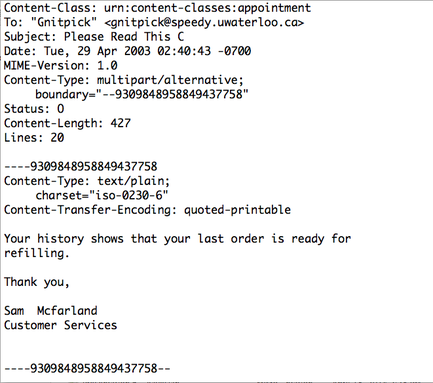
An example of an email in the data set.
After removing HTML tags and extracting the relevant text, additional pre-processing must be done to create the feature matrix. A detailed example of these pre-processing steps is shown below. Python NLTK (Natural Language Toolkit) is used in this project to perform pre-processing.
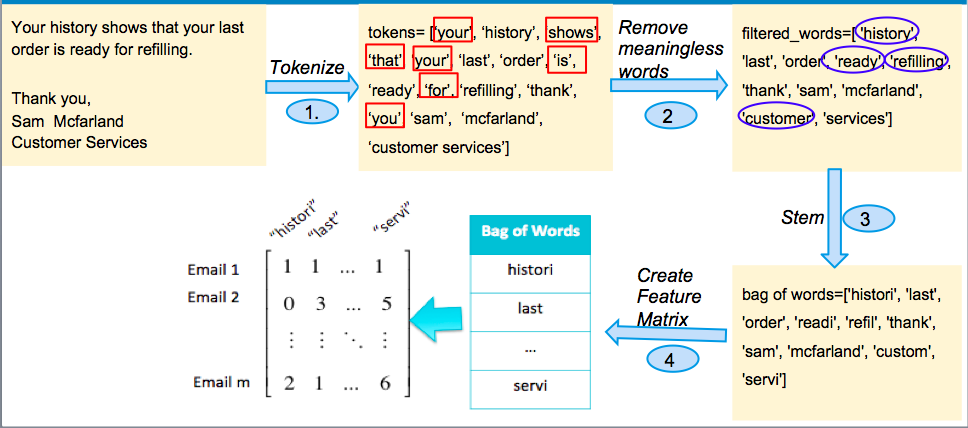
The steps required to create a feature matrix from relevant text.
After preliminary pre-processing (removing HTML tags and headers from the email in the data set), we take the following steps:
- Tokenize - We create "tokens" from each word in the email by removing punctuation.
- Remove meaningless words - The text in red squares are stop-words, which should be removed. Stop-words do not provide meaningful information to the classifier, and they increase dimensionality of feature matrix. In addition to many stop-words, we removed words over 12 characters and words less than three characters.
- Stem - The text in blue circle is converted to its "stem". Similar words are converted to its stem in order to form a better feature matrix. This allows words with similar meanings to be treated the same. For example, history, histories, historic will be considered same word in the feature matrix. Each stem is placed into our "bag of words", which is just a list of every stem used in the dataset.
- Create feature matrix - After creating the "bag of words" from all of the stems, we create a feature matrix. The feature matrix is created such that the entry in row i and column j is the number of times that token j occurs in email i.
Pre-processing: Reducing the Dimensionality
We would like the dimensionality of the feature matrix to be as small as possible, while still achieving high performance. However, using just the methods described above, our feature matrix becomes very large, very quickly. After considering only 70 emails, our feature matrix grows to have over 9000 features. We implementing a hash table, which allowed us to group features together. The hash table works as follows:

The steps required in hashing.
Each stem in the bag of words comes with a built-in hash index. We can then decide how many hash buckets (or features) we would like to have. We take the hash index mod the bucket size (divide by the bucket size and take the remainder) to find the new hashed index. This allows us to group several features together.
