The results were based on a training sample of 800 emails and a testing sample of 200 emails. This means our classifiers learned from the data in the training set of 800 emails. Then, we determined the performance of the classifiers by observing how the 200 emails in the testing set were classified.
Performance Metrics
The following metrics are used to measure a classifier's performance:
• Accuracy: % of predictions that were correct
• Recall: % of spam emails that were predicted correctly
• Precision: % of emails classified as spam that were actually spam
• F-Score: a weighted average of precision and recall
• Accuracy: % of predictions that were correct
• Recall: % of spam emails that were predicted correctly
• Precision: % of emails classified as spam that were actually spam
• F-Score: a weighted average of precision and recall
Performance for Different Number of Hash Buckets
As described in the pre-processing section, we can combine features by using hashing. This reduces the dimensionality of our feature matrix, which reduces run time. However, by combining features, the performance of the classifiers could potentially become worse.
However, we discovered that reducing the dimensionality did not have a large effect on most of our classifiers. The One-Nearest Neighbor and Logistic Regression classifiers were unaffected by the number of hash buckets used. The Naive Bayesian classifier performed better with a largest number of hash buckets, while the ID3 Decision Tree performed best with 1024 hash buckets. For future performance analysis, we used 1024 hash buckets.
However, we discovered that reducing the dimensionality did not have a large effect on most of our classifiers. The One-Nearest Neighbor and Logistic Regression classifiers were unaffected by the number of hash buckets used. The Naive Bayesian classifier performed better with a largest number of hash buckets, while the ID3 Decision Tree performed best with 1024 hash buckets. For future performance analysis, we used 1024 hash buckets.
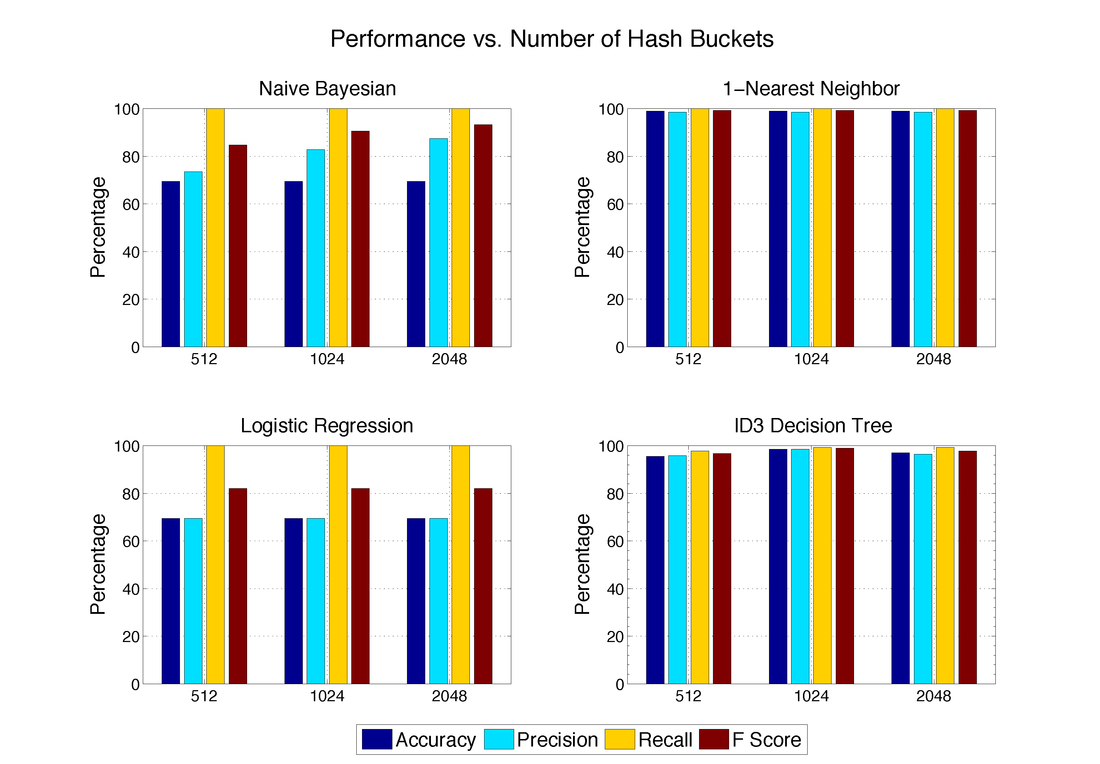
The number of hash buckets used did not have a large effect on performance for the 1-Nearest Neighbor, ID3 Decision Tree, and Logistic Regression algorithms. However, the precision of the Naive Bayesian classifier increased from 73.5% when using 512 hash buckets to 87.4% when using 2048 hash buckets.
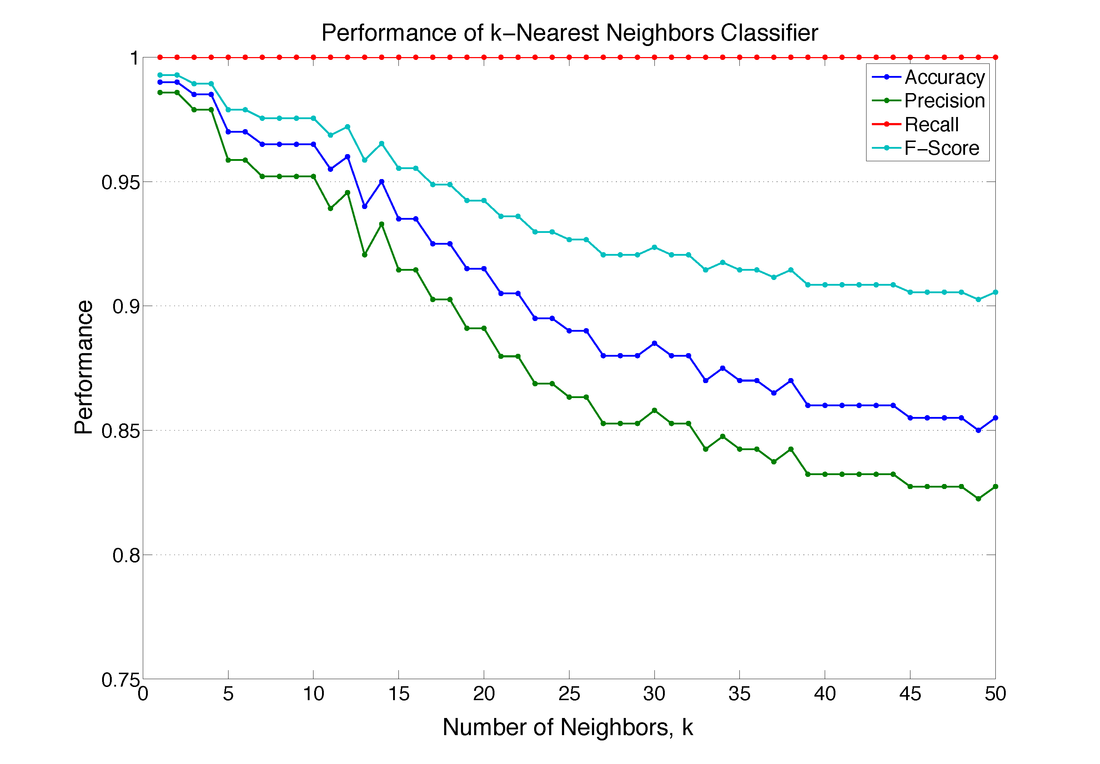
k-Nearest Neighbors Performance
The performance of the k-Nearest Neighbors classifier depends on the number of neighbors, k, that we consider in our majority vote. The figure below shows the performance of the k-Nearest Neighbor classifier as the value of k is increased. Interestingly, the One-Nearest Neighbor classifier (k-Nearest Neighbor with k = 1) performed the best.
Performance of Different Classifiers
Using a 1024 hash buckets, we compared the performance of the different classifiers.
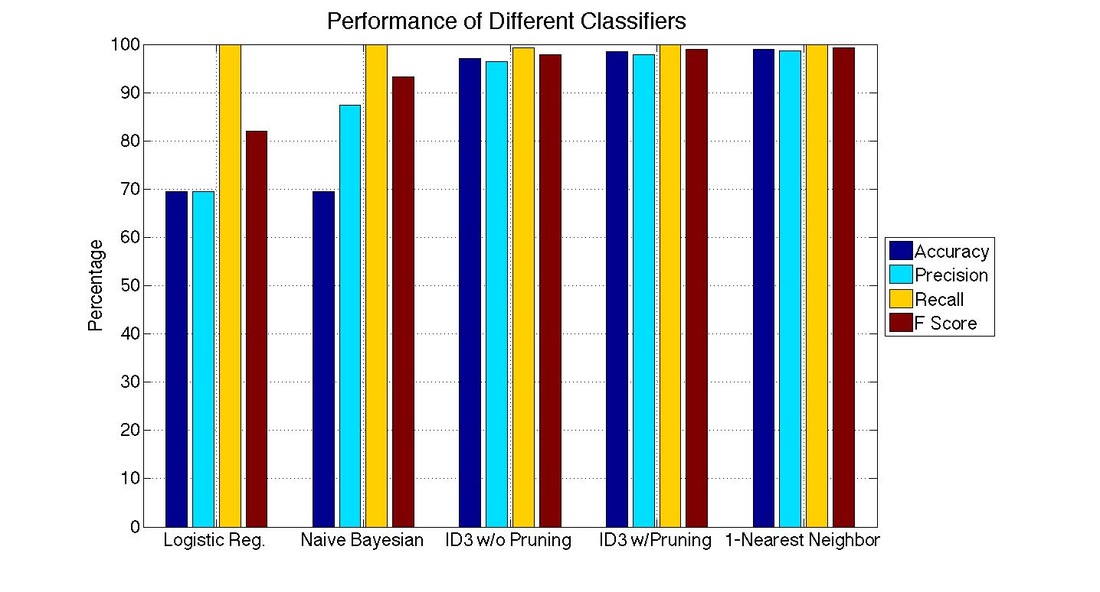
The One-Nearest Neighbor algorithm performed the best with the following performance metrics:
The ID3 Decision Tree algorithm also performed well.
- Accuracy 99.00%
- Precision 98.58%
- Recall 100%
- F Score 99.29%
The ID3 Decision Tree algorithm also performed well.
|
Pruned ID3 Decision Tree
|
ID3 Decision Tree without Pruning
|
Conclusion
We found that the One-Nearest Neighbor algorithm outperformed the other classifiers. This simple algorithm achieved great performance and was easy to implement. However, we believe that the performance of this algorithm could still be improved. We encourage those who wish to further this research to investigate the effects of a weighted majority vote, enhanced feature selection, and different distance measures.
Another key finding was that we discovered that the recall for all of the algorithms was very high, while the precision was lower. This suggests that our algorithms are very liberal in labeling an email as spam. To combat this, perhaps mapping the features to a higher dimension would aid in this problem. Some machine learning algorithms, such as Support Vector Machines, use this approach.
Overall, we believe that a machine learning approach to spam filtering is a viable and effective method to supplement current spam detection techniques.
We found that the One-Nearest Neighbor algorithm outperformed the other classifiers. This simple algorithm achieved great performance and was easy to implement. However, we believe that the performance of this algorithm could still be improved. We encourage those who wish to further this research to investigate the effects of a weighted majority vote, enhanced feature selection, and different distance measures.
Another key finding was that we discovered that the recall for all of the algorithms was very high, while the precision was lower. This suggests that our algorithms are very liberal in labeling an email as spam. To combat this, perhaps mapping the features to a higher dimension would aid in this problem. Some machine learning algorithms, such as Support Vector Machines, use this approach.
Overall, we believe that a machine learning approach to spam filtering is a viable and effective method to supplement current spam detection techniques.
